Dima Damen Professor of Computer Vision,
School of Computer Science,
Professor of Computer Vision,
School of Computer Science,Lead of Machine Learning and Computer Vision Group, University of Bristol EPSRC Early Career Fellow (2020-2025) Senior Research Scientist, Google DeepMind |
NewsNov 2025. Our paper PointSt3R is accepted at WACV. Oct 2025: Two ICCV 2025 Keynotes (DataCV and Ego360 workshops) are available in talks section Sep 2025: My PAISS 2025 tutorial on Video Understanding Out of the frame is available in talks section July 2025: Congratulations to Adriano Fragomeni who passed his viva - thanks to external examiner Pascal Mettes (UoA) for time and effort. Jan 2025: I will be giving keynotes at SCIA 2025 (June), ICVSS 2025 (July) and GCPR 2025 (Sep) Dec 2024: Our paper "It's Just Another Day: Unique Video Captioning by Discriminative Prompting" was selected as Best Paper at ACCV 2024 in Hanoi, Vietnam Nov 2024: Selected as Fellow @ELLIS for Europe Nov 2024: Journal extended version of our ICASSP 2023 paper "EPIC-SOUNDS" is now available on ArXiv Oct 2024: Our Survey paper "An Outlook into the Future of Egocentric Vision" appeared in Vol 132 at IJCV in its final format Sep 2024: Our ECCV 2024 paper AMEGO is now on ArXiv. Check Website for paper, code and benchmark Sep 2024: Online Open Access of our PAMI 2024 paper is now Online May 2024: Online Open Access of our IJCV 2024 paper is now Online
Feb 2024: 1st EgoVis (Joint) Workshop will be held @CVPR2024 - Jan 2024: Applications for Summer of Research have now closed. Results are expected 20 Feb. Nov 2023: Applications for Summer of Research @Bristol 2024 are now open [DL 19 Jan 2024] Oct 2023: Our BMVC'23 paper "Learning Temporal Sentence Grounding From Narrated EgoVideos" now available on ArXiv Sep 2023: EPIC Fields paper accepted at NeurIPS 2023 Aug 2023: Survey paper "An Outlook into the Future of Egocentric Vision" open for comments on OpenReview until 15 Sep. All major corrections/suggestions will be acknowledged in revised version. Aug 2023: Our paper "Learning Temporal Sentence Grounding From Narrated EgoVideos" was accepted ab BMVC 2023. Preprint coming soon July 2023: Our paper "What can a cook in Italy teach a Mechanic in India?" was accepted at ICCV 2023. Dataset and Code are public June 2023: I'll be giving a keynote at WACV 2024 next Jan. June 2023: Winners of the 2023 EPIC-KITCHENS challenges announced [Closed for applications]
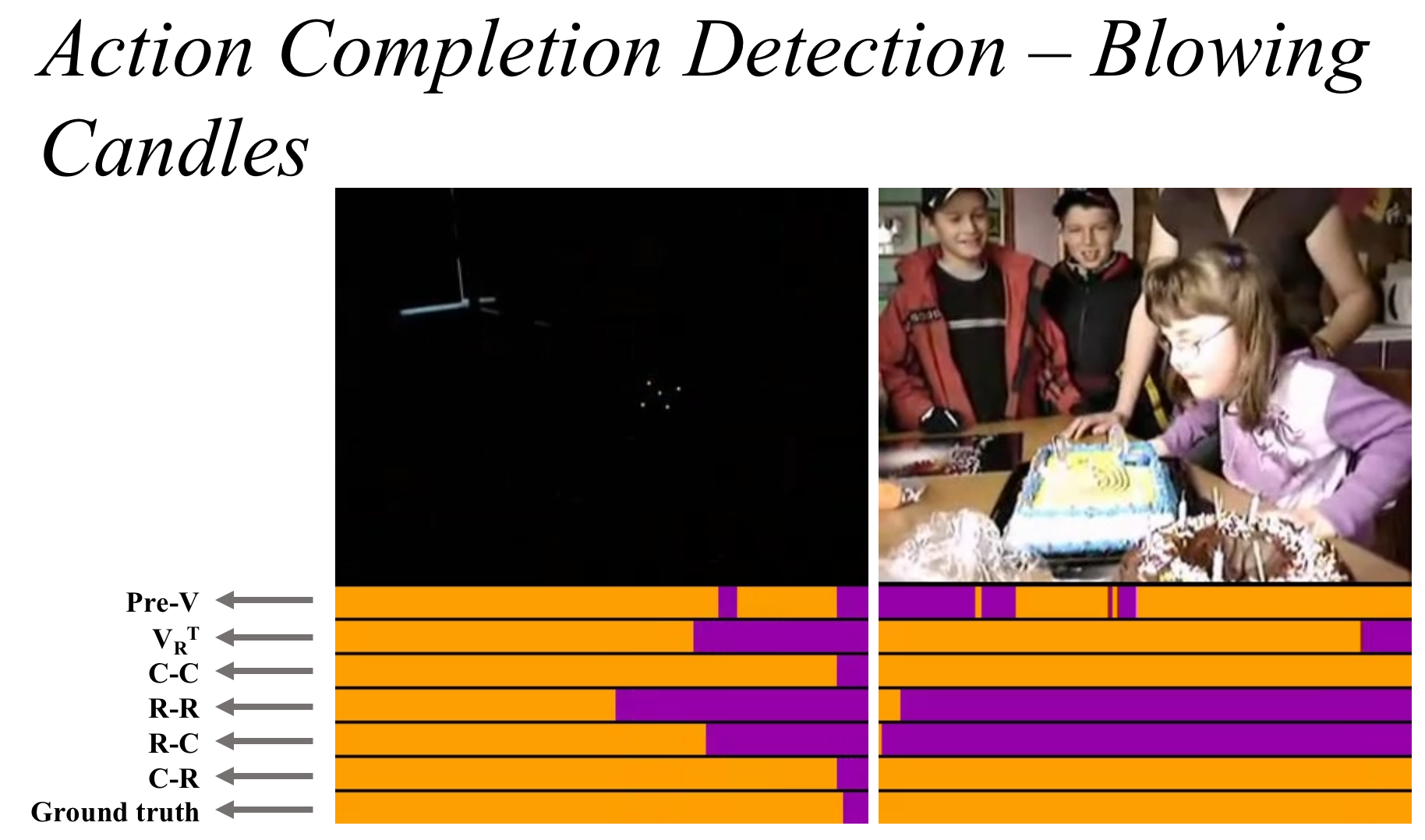
Feb 2023: Two papers accepted at CVPR 2023 Feb 2023: Two papers accepted at ICASSP 2023: Play-It-Back and EPIC-SOUNDS Feb 2023: On a research visit to UC Berkeley Jan 2023: EPIC-SOUNDS dataset publicly available Oct 2022: Our paper ConTra accepted as an oral at ACCV 2022 Sep 2022: VISOR and EgoClip papers accepted at NeurIPS 2022
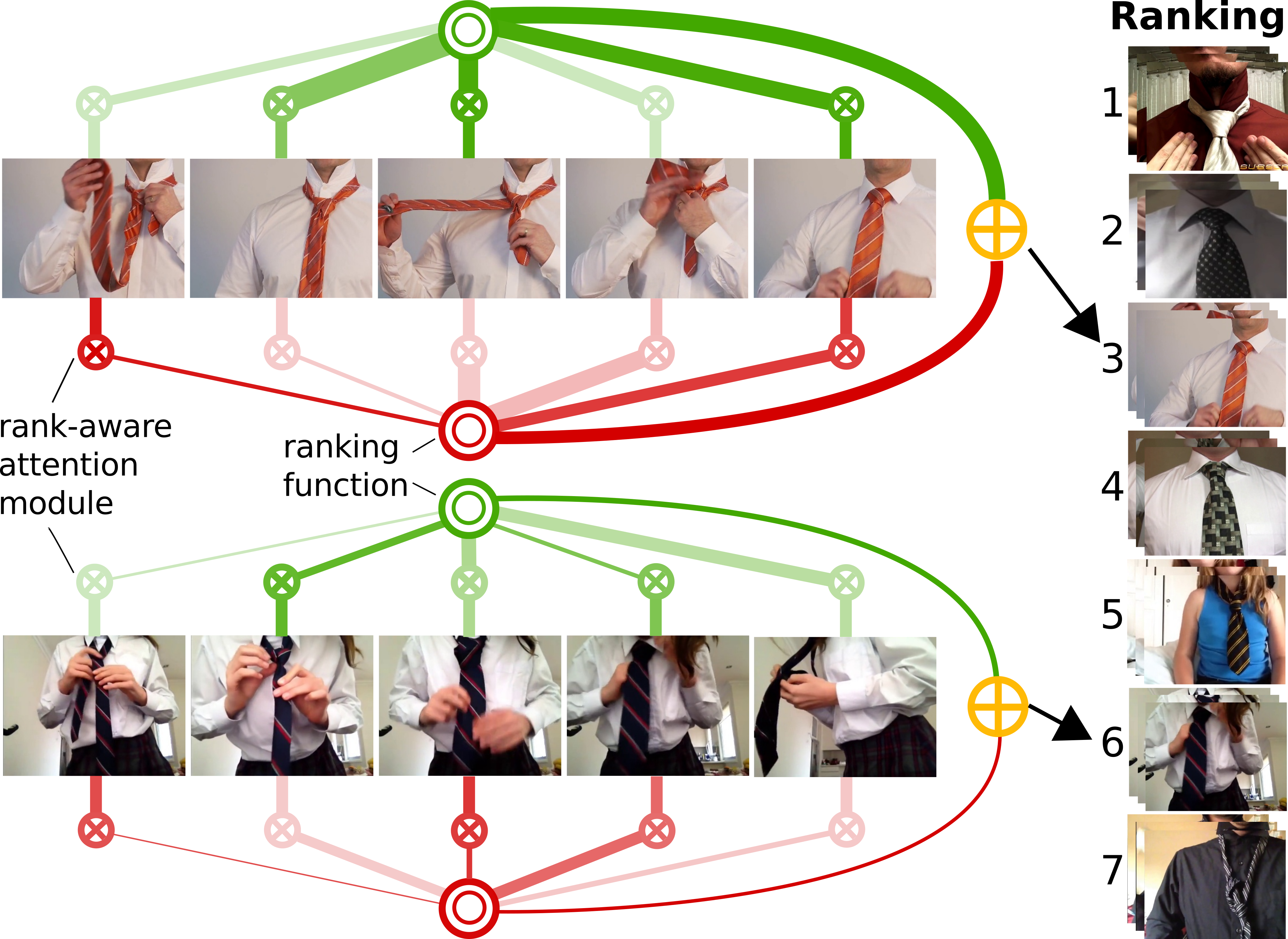
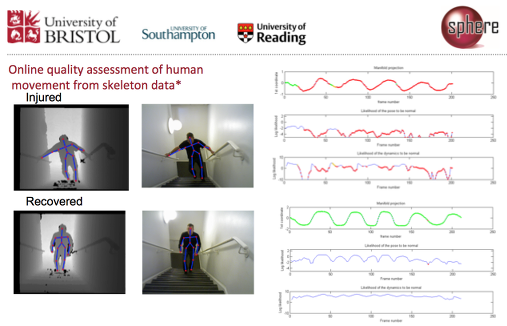
Aug 2022: Rleased VISOR Benchmark: Video Segmentations and Object Relations. Watch the Trailer June 2022: ran the Joint 10th EPIC Workshop and 1st Ego4D workshop alongside CVPR 2022 in New Orleans Mar 2022: Two papers accepted at CVPR 2022. Feb 2022: Ego4D Dataset is now publicly available Jan 2022: Dec 2021: New ArXiv Paper: UnweaveNet: Unweaving Activity Stories Nov 2021: Our BMVC 2021 paper "With a little help from my temporal context" is now Available on ArXiv Oct 2021: Ego4D Project and ArXiv paper now out. Reveal session during EPIC@CCV2021 Sep 2021: Our paper Rescaling Egocentric Vision accepted at IJCV Aug 2021: Welcoming Alexandros Stergiou and Bin Zhu as postdocs to the group July 2021: Technical report for 2021 EPIC-KITCHENS challengs is online June 2021: Our paper Slow-Fast Auditory Streams won outstanding paper at ICASSP 2021 (3 out of 1700 papers awarded) June 2021: EPSRC Program Grant Visual AI has a live website now June 2021: Pleased to be outstanding reviewer for CVPR 2021 May 2021: During CVPR 2021, I'll be delivering keynotes during 2nd comprehensive tutorial on Video understanding, 8th workshop on FGVC and 2nd HVU workshop, in addition to co-organising 8th EPIC@CVPR2021 Mar 2021: CVPR 2021 paper "On Semantic Similarity in Video Retrieval" now on ArXiv Mar 2021: CVPR 2021 paper "Temporal-Relational CrossTransformers for Few-Shot Action Recognition" now on ArXiv Feb 2021: Will be delivering keynotes at two CVPR2021 workshops: Fine-grained visual categorisation (FGVC8) and Holistic Video Understanding (HVU) Jan 2021: Slides for my talk at HAU@ICPR 2021 workshop can be found here Nov 2020: Two papers presented at ACCV 2020: Play Fair: Frame Attributions in Video Models (Project) and Nov 2020: Excited to start active work as Program Chair for ICCV 2021 in Montreal Sep 2020: Glad to join the ELLIS (European Laboratory for Learning and Intelligent Systems) Society as a member Sep 2020: Will be giving a keynote at the Deep Video Understanding workshop alongside ICMI 2020 Sep 2020: Will be giving a keynote at the HCMA workshop alongside ACM MM on 12 Oct Aug 2020: Final program for our EPIC@ECCV Workshop is now available online 1 July 2020: EPIC-KTICHESN-100 Dataset Now Released - Download, webinar June 2020: ArXiv Manuscript "Rescaling Egocentric Vision" is now online June 2020: Will be happy to deliver keynotes in August at ECCV workshops: Women in Computer Vision and Compositional and Multimodal Video Perception Challenge Jun 2020: Proud to be an Outstanding Reviewer for CVPR 2020. Jun 2020: My talk on "Learning from Narrated Videos of Everyday Tasks" at the CVPR2020 workshop on Instructional Videos is now available online Jun 2020: Deadline for the 7th EPIC@ECCV2020 Workshop is 10th of July - published proceedings included Apr 2020: EPSRC Program Grant Visual AI approved for funding. Mar 2020: I join the editorial board of IJCV as an associate editor. Mar 2020: Our paper "Action Modifers: Learning from Adverbs in Instructional Videos", accepted at CVPR 2020 is now on ArXiv - watch the video that explains the method here Mar 2020: Our paper "Multi-Modal Domain Adaptation for Fine-Grained Action Recognition", accepted for Oral at CVPR 2020 is now on Arxiv - see project details Feb 2020: Two papers accepted in CVPR 2020 - available in Arxiv already (see publications) Dec 2019: Jade-2 HPC Cluster has been accepted for funding Dec 2019: My talk at NCVPRIPG2019 in Hubli India is available here Dec 2019: I start EPSRC Early Career Fellowship UMPIRE this Jan. 5-Years Funding to expand my research activities in object interaction understanding. Nov 2019: I join the editorial board of IEEE TPAMI as associate editor Nov 2019: Congrats to Davide Moltisanti and Michael Wray for passing their PhD vivas Oct 2019: My talk from the Extreme Vision ICCV workshop is available here Oct 2019: Videos of all talks in our BMVA symposium are on available on YouTube Oct 2019: Videos of my 4-hour tutorial at North African Summer School in Machine Learning are now on YouTube: Part1, Part2 Sep 2019: Our paper "Retro-Actions: Learning 'Close' by Time-Reversing 'Open' Videos" (ICCVW) is now on Arxiv - Details Aug 2019: We release pretrained models and technical report for action recognition on EPIC-Kitchens July 2019: Our paper "Learning Visual Actions Using Multiple Verb-Only Labels" accepted for presentation at BMVC2019 is available on Arxiv July 2019: Two papers accepted at ICCV 2019, "EPIC-Fusion: Audio-Visual Temporal Binding for Egocentric Action Recognition" with Evangelos Kazakos (Bristol), Arsha Nagrani and Andrew Zisserman (Oxford), and "Fine-Grained Action Retrieval through Multiple Parts-of-Speech Embeddings" with Mike Wray (Bristol), Gabriela Csurka and Diane Larlus (Naver Labs) July 2019: I'll be giving keynotes at the ICCV2019 workshop YouTube8M, ICCV2019 workshop ACVR, and at the BMVC2019 workshop EgoApp July 2019: CFP BMVA symposium on Video Understanding in London - 25 Sep June 2018: Slides from my tutorial at North African Summer School in Machine Learning (NASSMA) are now online Apr 2019: Camera ready version and details of our paper Dual-Domain LSTM for Cross-Dataset Action Recognition - CVPR 2019 now online Apr 2019: Camera ready version and details of our paper The Pros and Cons: Rank-aware Temporal Attention for Skill Determination in Long Videos - CVPR 2019 now online Apr 2019: Fifth EPIC workshop accepted - EPIC@ICCV2019 will be held in Seoul this Oct/Nov Apr 2019: Will be giving a keynote at the 7th Workshop on Assistive Computer Vision and Robotics alongside ICCV in Seoul this October. Apr 2019: Camera ready version and details of our paper Action Recognition from Single Timestamp Supervision in Untrimmed Videos - CVPR 2019 now online and on Arxiv Mar 2019: Looking forward to returning as a speaker for the 2019 BMVA summer school in Lincoln this June Mar 2019: Slides for my keynote at VISAPP now online Mar 2019: Invited as one of the speakers at the First North African summer school in Machine Learning NASSMA Feb 2019: Three papers accepted at CVPR 2019 (coming soon on Arxiv) Feb 2019: Keynote at VISAPP 2019 in Prague Dec 2018: EPIC@CVPR2019 Workshop to take place in Long Beach Oct 2018: Scheduled talk at MPI Tubingen - details Sep 2018: EPIC-KITCHENS presented as Oral at ECCV 2018 - camera ready available Arxiv, Webpage Sep 2018: Leaderboards for the EPIC-KITCHENS challenges on CodaLab are now open Sep 2018: Two papers presented at BMVC 2018. Action Completion (Dataset) and CaloriNet Aug 2018: EPIC-SKILLS dataset, for our CVPR2018 paper is now online Aug 2018: Programme for EPIC@ECCV2018 workshop is now available. Join us in Munich on Sep 9th July 2018: Looking forward to giving a tutorial on egocentric vision as part of the BMVA Summer School on July 5th, University of East Anglia. Apr 2018: EPIC-KITCHENS 2018 goes live today: 11.5M Frames, full HD, 60fps, head-mounted, 32 kitchens from 4 cities (in North America and Europe), 10 nationalities. FULLY annotated: 40K action segments, 454K object bounding boxes. Dataset: http://epic-kitchens.github.io Details at: Arxiv Apr 2018: Our paper "Human Routine Change Detection using Bayesian Modelling" accepted at ICPR2018, to be presented in Beijing this August. Details Feb 2018: Our paper "Who's Better, Who's Best" accepted at CVPR2018, to be presented in Salt Lake city this June. Details Feb 2018: Congrats to Yangdi Xu for passing his PhD viva with minor corrections Jan 2018: Serving on the High Performance Computing exec board at UoB Oct 2017: Selected as outstanding reviewer at ICCV 2017 Oct 2017: Well-attended Second Int. Egocentric Perception Interaction and Computing (EPIC) workshop alongside ICCV in Venice Oct 2017: Our paper "Trespassing the Boundaries: Labeling Temporal Bounds for Object Interactions in Egocentric Video" was presented in ICCV - details Oct 2017: Our paper "Recurrent Assistance: Cross-Dataset Training of LSTMs on Kitchen Tasks" was presented at ACVR - pdf Sep 2017: Unit details for the new Applied Deep Learning M level unit - Uni Catalogue Sep 2017: Serving as associate editor for Pattern Recognition Aug 2017: Happy to be working as a consultant with Bristol's Cookpad on developing their Computer Vision and Machine Learning agenda Apr 2017: 6 July - Lincoln, BMVA summer school, will be giving a tutorial on Egocentric Vision Apr 2017: 15 May - Bristol, will be giving a public talk on 'What can a wearable camera know about me?' Mar 2017: Slides from my talk on Challenges and Opportunities for Action and Activity Recognition using RGBD Data, BMVA Symposium are now available Feb 2017: Videos from BMVA symposium on Transfer Learning now available Dec 2016: Final programme for BMVA Symposium on Transfer Learning now available Oct 2016: Code Released for 3DV paper on acquisition and registration of point clouds using two facing Kinects Sep 2016: 3D Data Acquisition and Registration Using Two Opposing Kinects - Paper accepted at 3DV Aug 2016: Action Completion paper accepted at BMVC and dataset released - Project Webpage Aug 2016: Nokia Technologies donation of €50K Press release Aug 2016: Action Completion paper accepted at BMVC, York, Sep 2016. project July 2016: PhD students Michael Wray and Davide Moltisanti awarded second poster prize at BMVA summer school news July 2016: CFP: Transfer Learning in Computer Vision - BMVA Symposium [details, dates and submission] Jun 2016: PhD opening in Computer Vision and Machine Learning (Home/EU students) - Open Until , ad on jobs.ac.uk Jun 2016: CVPR 2016 Demo for GlaciAR May 2016: EPIC@ECCV2016 Workshop (Egocentric Perception, Interaction and Computing) Accepted. Apr 2016: EPSRC Project LOCATE to be funded starting July 2016 Mar 2016: You-Do, I-Learn: Egocentric Unsupervised Discovery of Objects and their Modes of Interaction Towards Video-Based Guidance accepted at CVIU Nov 2015: EPSRC Project GLANCE to be funded starting March 2016 Sep 2015: Paper "Unsupervised Daily Routine Modelling from a Depth Sensor using Bottom-Up and Top-Down Hierarchies" accepted at ACPR Sep 2015: Paper "Estimating Visual Attention from a Head Mounted IMU" presented at ISWC in Okasa, Japan Sep 2015: Paper "Real-time RGB-D Tracking with Depth Scaling Kernelised Correlation Filters and Occlusion Handling" Presented at BMVC Aug 2015: PhD Student Vahid Soleiman publishes paper on Remote Pulmonary Function Testing using a Depth Sensor at BIOCAS 2015. Demo Video June 2015: PLOSONE article available online June 2015: SI on cognitive robotics systems: concepts and applications at the Journal of Intelligent & Robotic Systems is online Mar 2015: Interdisciplinary research internship awarded for CS student Hazel Doughty. Sep 2014: Paper "You-Do, I-Learn: Discovering Task Relevant Objects and their Modes of Interaction from Multi-User Egocentric Video" presented at BMVC Sep 2014: Paper "Online quality assessment of human movement from skeleton data" presented at BMVC Sep 2014: Paper "Multi-user egocentric Online System for Unsupervised Assistance on Object Usage" presented at ECCVW (ACVR 2014) Aug 2014: C++ code (improved performance v 1.2) and Android apk for real-time object detector available. July 2014: The Bristol Egocentric Object Interactions Dataset has now been released July 2014: Book review published in IAPR newsletter July 2014: Video lectures from BMVC 2013 are now available online. July 2014: Sphere project's website irc-sphere.ac.uk has now been released (2013-2018). May 2014: Project Ideas for 3G403 and 2G400 students available. Feb 2014: PhD Opening in Ego-centric Vision - apply as soon as possible... Nov 2013: Project GlaciAR is starting funded by Samsung's GRO 2013 Awards Nov 2013: Cognitive Robotics Systems (CRS 2013) (IROS 2013 workshop), successfully concludes at Tokyo, Japan. Sep 2013: BMVC 2013 successfully concluded at Bristol Aug 2013: Outstanding Reviewer award at IEEE AVSS 2013. June 2013: Outstanding Reviewer award at IEEE CVPR 2013. May 2013: New bug-fixed version (v1.1) of our Multi-Object Detector (MOD) code is now available online |





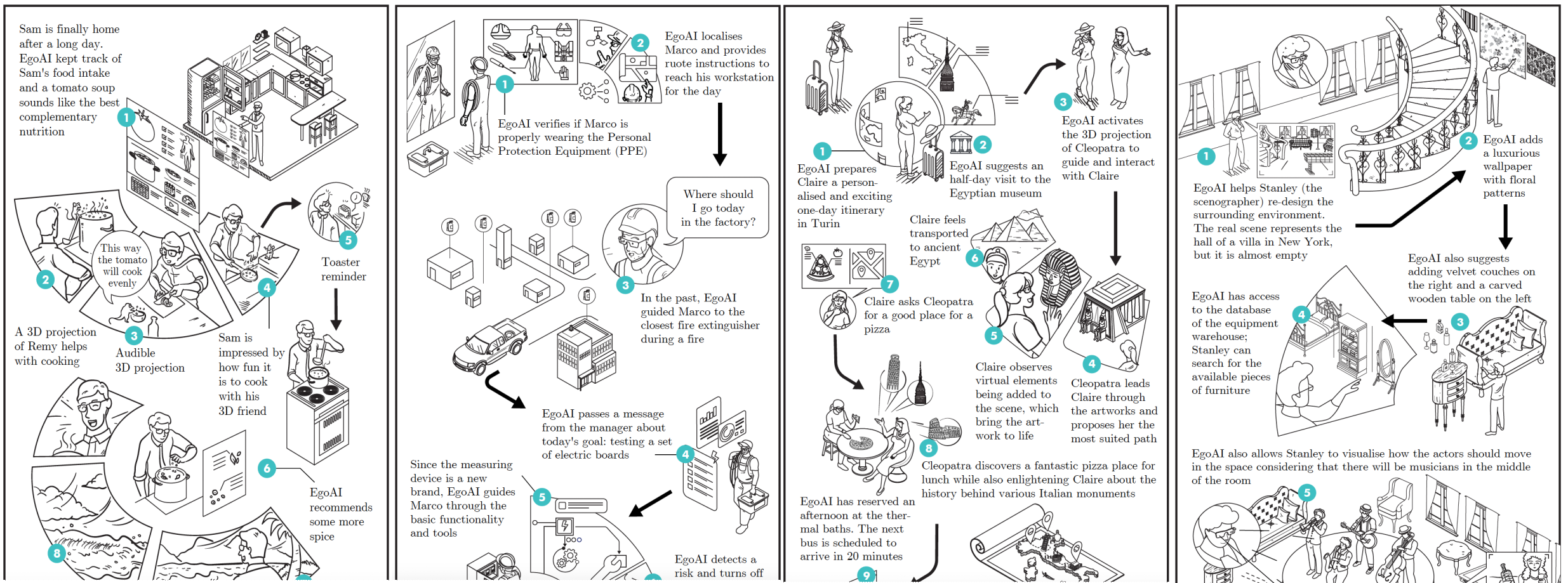
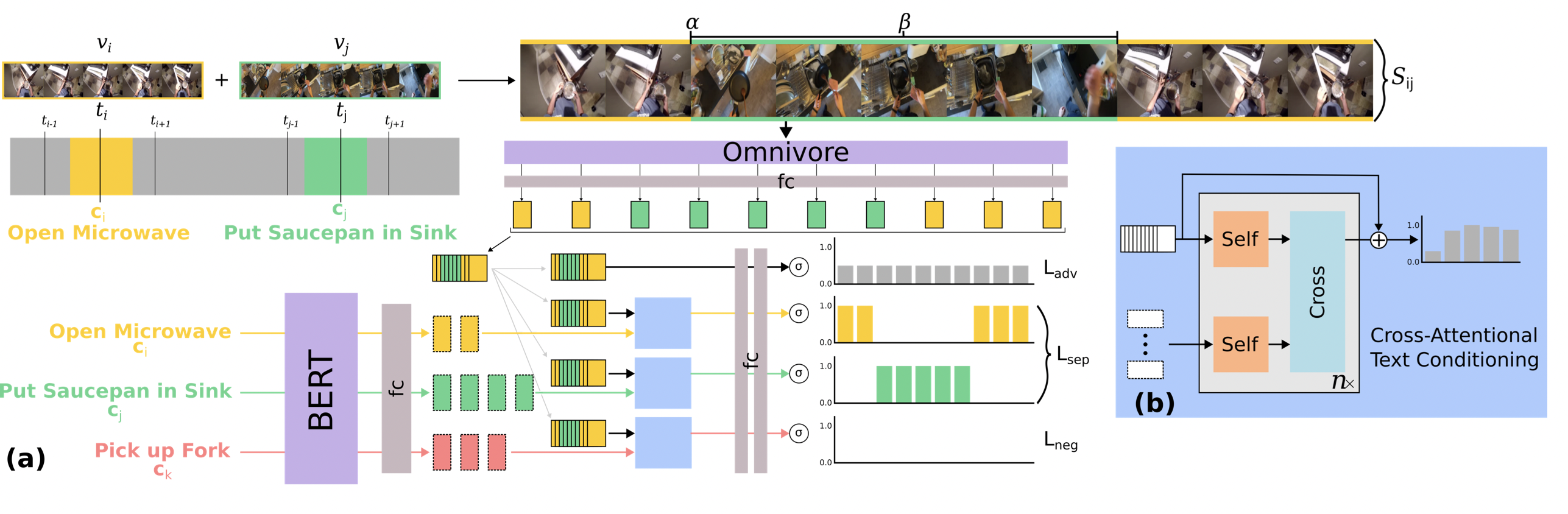

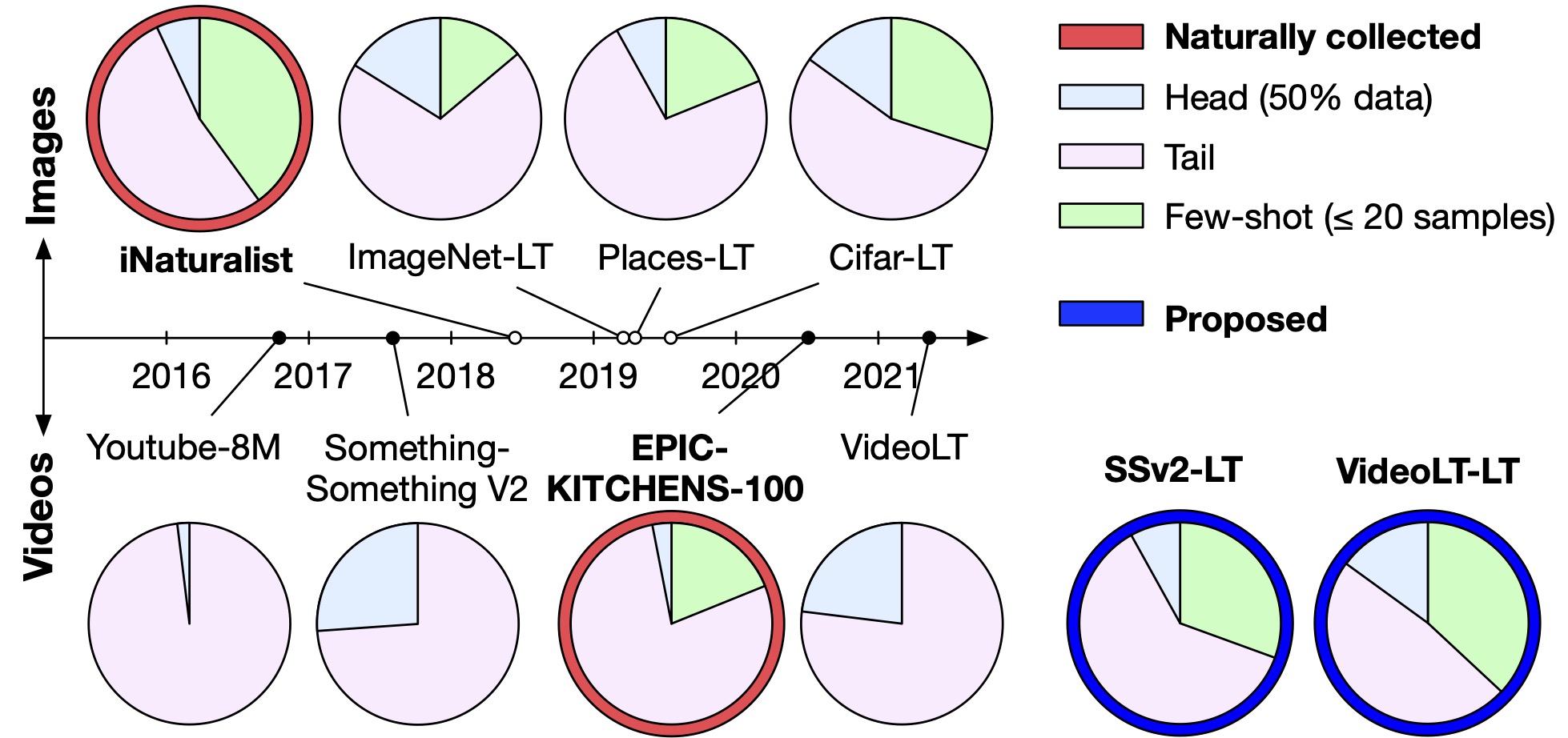
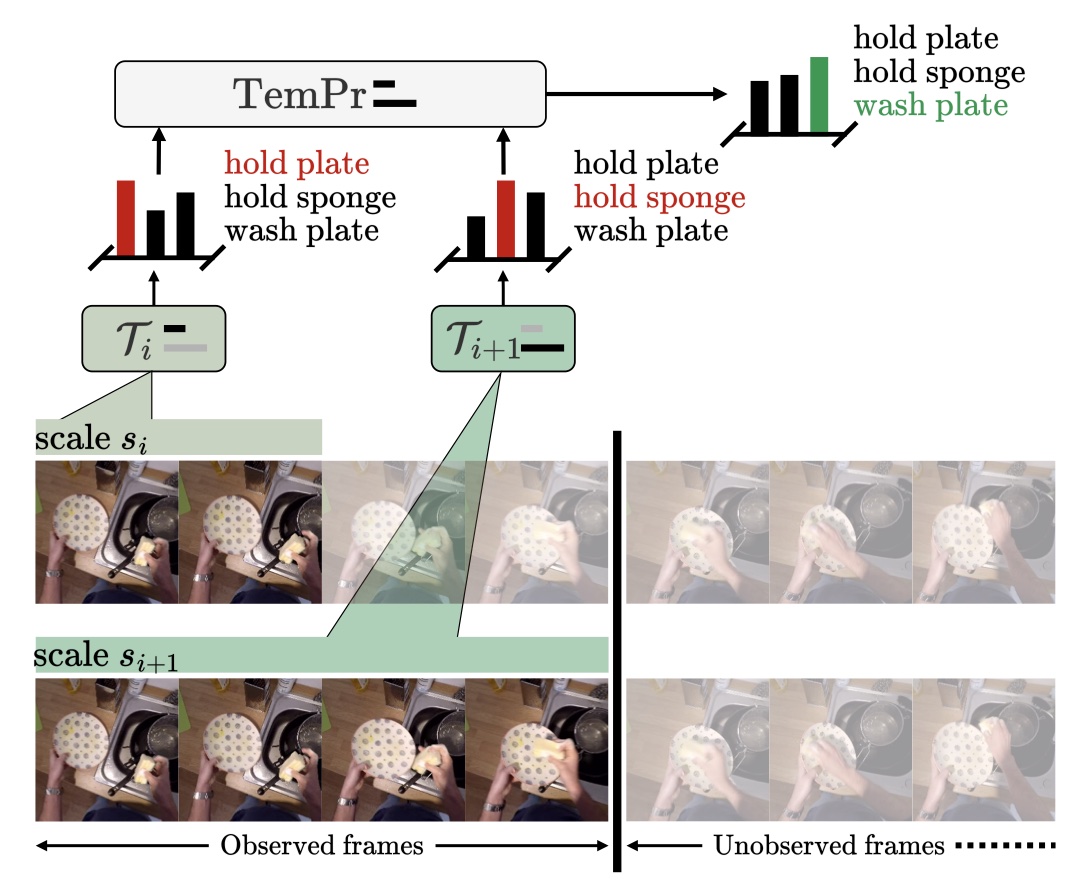













{kind=link}
{kind=link}