Action Recognition from Single Timestamp Supervision in Untrimmed Videos
CVPR 2019
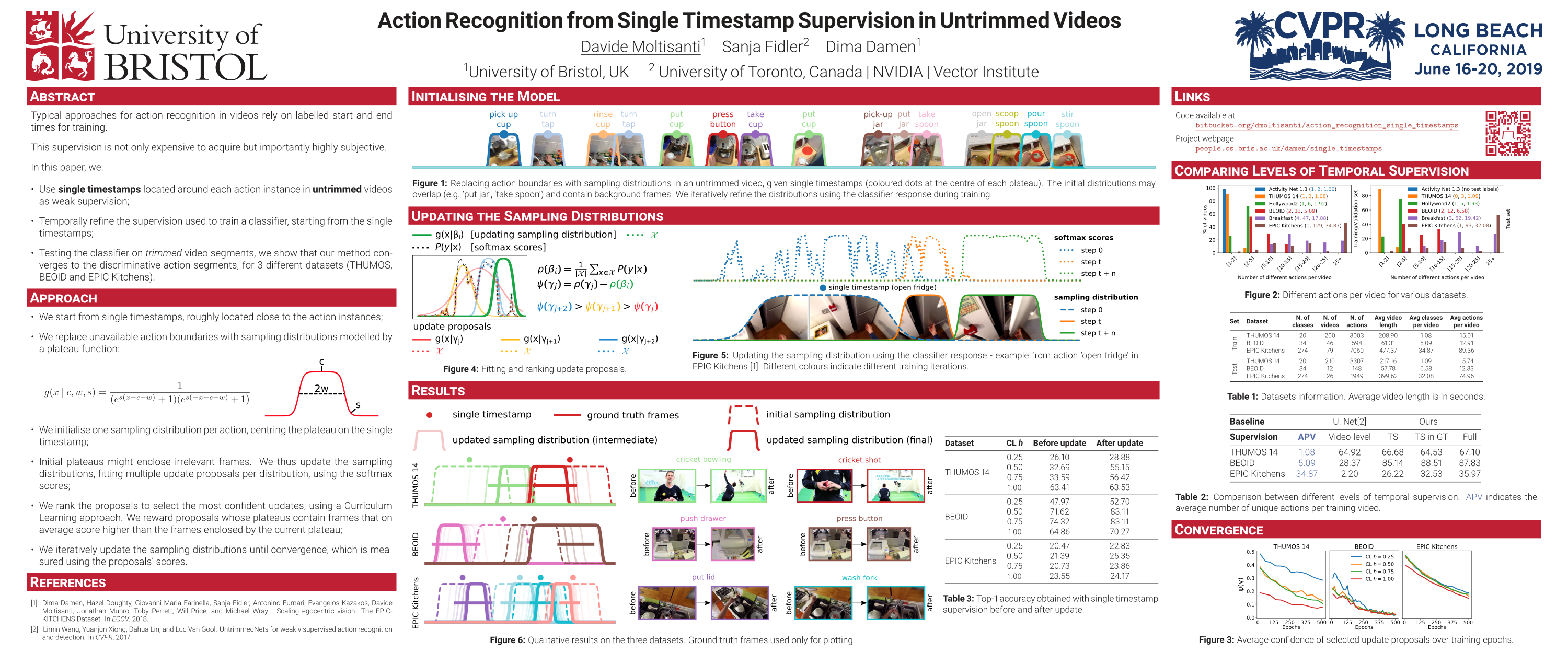
Labelling the start and end times of actions in long untrimmed videos is not only expensive, but often ambiguous.
In this work, we use cheaper roughly-aligned labels. These are one timestamp per action, close to (but not necessarily within) the action instance (see the coloured dots).
We propose a method that starts from sampling distributions initialised from these single timestamps.
The initial distributions (top) may overlap and contain background frames.
We iteratively refine the locations and temporal extent of these distributions (bottom) using the classifier response during training.
We evaluate our method on three datasets for fine-grained recognition: THUMOS, BEOID and EPIC-Kitchens.
Our work demonstrates that the sampling distributions converge to the location and extent of discriminative action segments.
Authors
Davide Moltisanti - University of Bristol, Visual Information Laboratory
Sanja Fidler - University of Toronto; NVIDIA; Vector Institute
Dima Damen - University of Bristol, Visual Information Laboratory
Abstract
Recognising actions in videos typically requires the start and end times of each action to be known.
This labelling is not only subjective, but also expensive to acquire.
We propose a method that uses single timestamps located around each action instance, in untrimmed videos, as opposed to the standard start/end times.
We replace expensive action bounds with sampling distributions initialised from these timestamps.
We then use the classifier's response to iteratively update the sampling distributions.
We demonstrate that these distributions converge to the location and extent of discriminative action segments.
We evaluate our method on three datasets for fine-grained recognition and show that single timestamps offer a
reasonable compromise between recognition performance and labelling effort, performing comparably to full temporal supervision.
Updating the sampling distribution using the classifier response.
Example from action 'open fridge' in EPIC Kitchens.
@InProceedings{moltisanti19action,
author = "Moltisanti, Davide and Fidler, Sanja and Damen, Dima",
title = "{A}ction {R}ecognition from {S}ingle {T}imestamp {S}upervision in {U}ntrimmed {V}ideos",
booktitle = "Computer Vision and Pattern Recognition (CVPR)",
year = "2019"}
A short history
For the first version of EPIC-KITCHENS we used a live-commentary approach (people narrating actions without pausing the video) to annotate the untrimmed videos.
The narration timestamps served as an initial ground to collect action boundaries and object boxes.
As we collected the dataset, we wondered if the rough narration timestamps could be used to supervise action recognition models.
We showed this is possible in this paper.
While working on the paper we realised we were missing many actions in the videos. This was because annotators did not pause the videos while they were speaking, and as a result they were naturally not able to narrate actions that were happening as they spoke. Moreover, the timestamps were often not well aligned with the videos.
For the EPIC-KITCHENS extension we wanted to fix these issues, i.e. we wanted dense and precise narration timestamps.
The EPIC Narrator was thus born! The tool allows easy annotations of actions in video through narration.
Importantly, the narrator dramatically increased annotation density and precision.
You can download the EPIC Narrator here.
You can find more about the benefits of using the narrator in our arXiv paper.
Research supported by: EPSRC LOCATE (EP/N033779/1) and EPSRC Doctoral Training Programme at the University of Bristol.
Part of this work was carried out during Davide's summer internship at the University of Toronto, working with Dr. Fidler.